Brostow, Shotton, Fauqueur, Cipolla (bibtex)
Pattern Recognition Letters (pdf)
Brostow, Fauqueur, Cipolla (bibtex)
Note:
Our 32 labels cover most of each image, but our own experiments were normally done with the some of the classes grouped together in a hierarchy. See the "CamToyota Class hierarchy" in Section IV of Classes.txt.
The database addresses the need for experimental data to quantitatively evaluate emerging algorithms. While most videos are filmed with fixed-position CCTV-style cameras, our data was captured from the perspective of a driving automobile. The driving scenario increases the number and heterogeneity of the observed object
classes.
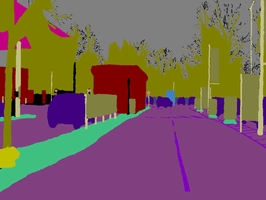
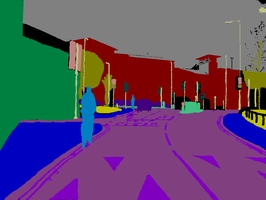
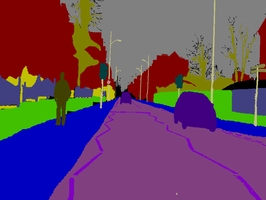
Over ten minutes of high quality 30Hz footage is being provided, with corresponding semantically labeled images at 1Hz and in part, 15Hz. The CamVid Database offers four contributions that are relevant to object analysis researchers. First, the per-pixel semantic segmentation of over 700 images was specified manually, and was then inspected and confirmed by a second person for accuracy. Second, the high-quality and large resolution color video images in the database represent valuable extended duration digitized footage to those interested in driving scenarios or ego-motion. Third, we filmed calibration sequences for the camera color response and intrinsics, and computed a 3D camera pose for each frame in the sequences. Finally, in support of expanding this or other databases, we offer custom-made labeling software for assisting users who wish to paint precise class-labels for other images and videos. We evaluated the relevance of the database by measuring the performance of an algorithm from each of three distinct domains: multi-class object recognition, pedestrian detection, and label propagation.

Avi, 30 Mb, xVid compressed. (playback tips or get the free Mac/Windows player.
or
Mpg, 11 Mb, mpeg-1 compressed (more compatible, but lower quality)

CamVid Database
(just samples shown. For all the videos, see below)
Link to codecs + utility for extracting frames from those big files (read the inventory.txt)
This folder should meet most of your needs, but let me know if not. In brief: Follow instructions in inventory.txt download the big files from the FTP server, install the Panasonic P2 driver for your OS, and run our MXF extractor, feeding it the right script. For the 01TP sequence, you'll also need the Lagarith lossless codec.
Labeled Images
(701 so far)
Link to zip file with painted class labels for stills from the video sequences.
Txt file listing classes and label colors as RGB triples (sorted).
(Note: the corresponding raw input images only - at 1Hz,
already extracted from the respective videos are here (556Mb).)
Camera Extrinsics
The relevant line that you care about to get the projection matrix of 1 camera is in MotBoostEvalOneFrame.m (see how LoadBoujou_2Dtrax_3dBans_Misc.m calls it):
curC = Cs( frameNum-offsetForFrameNums, 1:3);
Intrinsics
Example camera pose trajectory, stored in Boujou Animation Format:
each line containing "AddDecompCameraKey" has a K and R matrix and t vector,
so that P = K * R * [I -t]

seq16E5

Description: 6120 frames at 30Hz == 3:24 min
Sample Frame
VideoFiles 1 and 2 in MXF format* (note: these are 2 halves of 1 zip file)
seq16E5_15Hz
(see also CamSeq01)

Description: 202 frames at 30Hz == 0:06 min
Sample Frame
VideoFiles 1 and 2 in MXF format* (note: same files as above, but use a different script)
seq05VD

Description: 5130 frames at 30Hz == 2:51 min
Sample Frame
VideoFile in MXF format*


| Moving objects Animal Pedestrian Child Rolling cart/luggage/pram Bicyclist Motorcycle/scooter Car (sedan/wagon) SUV / pickup truck Truck / bus Train Misc |
Road Road == drivable surface Shoulder Lane markings drivable Non-Drivable |
Ceiling Sky Tunnel Archway |
Fixed objects Building Wall Tree Vegetation misc. Fence Sidewalk Parking block Column/pole Traffic cone Bridge Sign / symbol Misc text Traffic light Other |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}