{kind=link}

W.B.Langdon . 11 Aug 2014 (full list)
Two page version presented at BNAIC 2002 (PDF, ps.gz) Summary
ABSTRACT
We model in detail the distribution of Boolean functions implemented by random non-recursive programs, similar to linear genetic programming (GP). Most functions are constants, the remainder are mostly simple.
Bounds on how long programs need to be before the distribution of their functionality is close to its limiting distribution are provided in general and for average computers.
Results for a model like genetic programming are experimentally tested.
Two page version presented at BNAIC 2002 (PDF, ps.gz)
ABSTRACT
Fitness distributions (landscapes) of programs tend to a limit as they get bigger. Markov chain convergence theorems give general upper bounds on the linear program sizes needed for convergence. Tight bounds (exponential in N, N log N and smaller) are given for five computer models (any, average, cyclic, bit flip and Boolean). Mutation randomizes a genetic algorithm population in 1/4(l+1)(log(l)+4) generations. Results for a genetic programming (GP) like model are confirmed by experiment.
ABSTRACT
Genetic programming (GP) offers a generic method of automatically fusing together classifiers using their receiver operating characteristics (ROC) to yield superior ensembles. We combine decision trees (C4.5) and artificial neural networks (ANN) on a difficult pharmaceutical data mining (KDD) drug discovery application. Specifically predicting inhibition of a P450 enzyme. Training data came from high throughput screening (HTS) runs. The evolved model may be used to predict behaviour of virtual (i.e. yet to be manufactured) chemicals. Measures to reduce over fitting are also described.
ABSTRACT
We have previously shown on a range of benchmarks [Langdon,2001] Genetic programming (GP) can automatically fuse given classifiers of diverse types to produce a combined classifier whose Receiver Operating Characteristics (ROC) are better than [Scott et al., 1998 BMVC]'s "Maximum Realisable Receiver Operating Characteristics" (MRROC). I.e. better than their convex hull. Here our technique is used in a blind trial where artificial neural networks are trained by Clementine on P450 pharmaceutical data. Using just the networks GP automatically evolves a composite classifier.
ABSTRACT
Genetic programming (GP) can automatically fuse given classifiers of diverse types to produce a combined classifier whose Receiver Operating Characteristics (ROC) are better than [Scott et al., 1998 BMVC]'s ``Maximum Realisable Receiver Operating Characteristics'' (MRROC). I.e. better than their convex hull. This is demonstrated on a satellite image processing bench mark using Naive Bayes, Decision Trees (C4.5) and Clementine artificial neural networks .
ABSTRACT
Genetic programming (GP) can automatically fuse given classifiers to produce a combined classifier whose Receiver Operating Characteristics (ROC) are better than [Scott et al., 1998 BMVC]'s ``Maximum Realisable Receiver Operating Characteristics'' (MRROC). I.e. better than their convex hull. This is demonstrated on artificial, medical and satellite image processing bench marks.
ABSTRACT
To investigate the fundamental causes of bloat, six artificial random binary tree search spaces are presented. Fitness is given by program syntax (the genetic programming genotype). GP populations are evolved on both random problems and problems with ``building blocks''. These are compared to problems with explicit ineffective code (introns, junk code, inviable code). Our results suggest the entropy random walk explanation of bloat remains viable. The hard building block problem might be used in further studies, e.g. of standard subtree crossover.
ABSTRACT
It has been suggested that the ``Maximum Realisable Receiver Operating Characteristics'' for a combination of classifiers is the convex hull of their individual ROCs [Scott et al., 1998 BMVC]. As expected in at least some cases better ROCs can be produced. We show genetic programming (GP) can automatically produce a combination of classifiers whose ROC is better than the convex hull of the supplied classifier's ROCs.
ABSTRACT
We evolve, using AIMGP machine code genetic programming, Discipulus, an approximation of the inverse kinematics of a real robotics arm with many degrees of freedom. Elvis is a bipedal robot with human-like geometry and motion capabilities - a humanoid, primarily controlled by evolutionary adaptive methods. The GP system produces a useful inverse kinematic mapping, from target 3-D points (via pairs of stereo video images) to a vector of arm controller actuator set points.
ABSTRACT
N grams offer fast language independent multi-class text categorization. Text is reduced in a single pass to ngram vectors. These are assigned to one of several classes by a) nearest neighbor (KNN) and b) genetic algorithm operating on weights in a nearest neighbour classifier. 91% accuracy is found on binary classification on short multi-author technical English documents. This falls if more categories are used but 69% is obtained with 8 classes.
Zipf law is found not to apply to trigrams.
ABSTRACT
In earlier work we predicted program size would grow in the limit at a quadratic rate and up to fifty generations we measured bloat O(generations**(1.2-1.5)). On two simple benchmarks we test the prediction of bloat O(generations**2.0) up to generation 600. In continuous problems the limit of quadratic growth is reached but convergence in the discrete case limits growth in size. Measurements indicate subtree crossover ceases to be disruptive with large programs (1,000,000) and the population effectively converges (even though variety is near unity). Depending upon implementation, we predict run time O(number of generations**(2.0-3.0)) and memory O(number of generations**(1.0-2.0)).
ABSTRACT
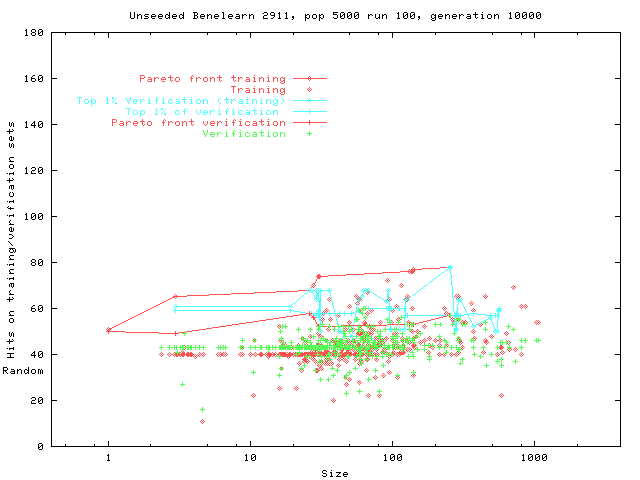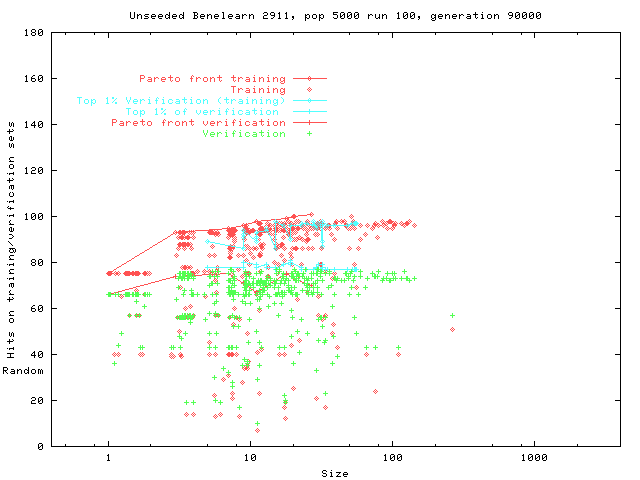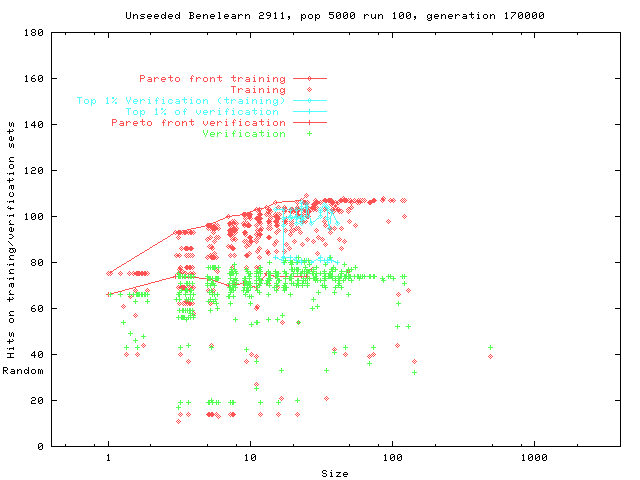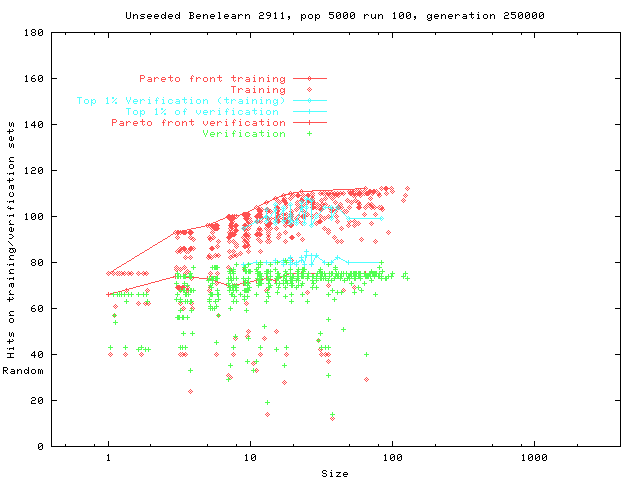
We show genetic programming (GP) populations can evolve under the influence of a Pareto multi-objective fitness and program size selection scheme, from ``perfect'' programs which match the training material to general solutions. The technique is demonstrated with programmatic image compression, two machine learning benchmark problems (Pima Diabetes and Wisconsin Breast Cancer) and an insurance customer profiling task (Benelearn99 data mining).
ABSTRACT
Size fair and homologous crossover genetic operators for tree based genetic programming are described and tested. Both produce considerably reduced increases in program size and no detrimental effect on GP performance. GP search spaces are partitioned by the ridge in the number of program versus their size and depth. A ramped uniform random initialisation is described which straddles the ridge. With subtree crossover trees increase about one level per generation leading to sub-quadratic bloat in length.
ABSTRACT
Presents summaries of published GP/EM literature, Internet based sources of GP/EM information and our plans for future reviews of GP/EM resources (books, world wide web (www) sites, products and programs).
Aninmated gif movie of evolution of the multi-objective Pareto front of the population in the run which evolved the answer (300kb).
ABSTRACT
The first genetic programming technique automatically evolved profiles of potential insurance customers the task is part of the Benelearn'99 competition. The information about customers consists of 86 variables and includes product usage data and socio-demographic data derived from zip codes. The data was supplied by the Dutch data mining company Sentient Machine Research, and is based on real world business data. Profiles which correctly identified more than 40 percent of customers were automatically evolved using genetic programming.
INTRODUCTION
It has been known for some time that programs within GP populations tend to rapidly increase in size as the population evolves [6]. If unchecked this consumes excessive machine resources and so is usually addressed either by enforcing a size or depth limit on the programs or by an explicit size component in the GP fitness. We show with standard subtree crossover and no limits programs grow in depth at a linear rate leading sub-quadratic increase in size. It might be assumed that such limits have little effect but GP populations are effected surprisingly quickly.
ABSTRACT
We investigate the distribution of fitness of programs represented as parse trees, particularly how such distributions scale with respect to changes in size of the programs. By using a combination of enumeration and Monte Carlo sampling on a large number of problems from three very different areas we are lead to suggest, in general, once some minimum size threshold has been exceeded, the distribution of performance is approximately independent of program length. In one special case we are able to prove this result. However we do note some exceptions where tiny fractions of the search space do not scale in the same way as the bulk of it. While we feel justified in our claim for functions (i.e. programs with out side effects) we have so far only conducted limited experiments with programs including side effects and iteration. These suggest a similar result may also hold for this wider class of programs.
Presented at
Schloss Dagstuhl
(report).
Presented at
GECCO'2000
Chapter 8 in
Advances in Genetic Programming 3,
MIT Press,
Cambridge, MA, USA, May 1999
ch08.ps.gz.
Slides, (187kb)
Java movie of evolution of best of generation phenotype, 276kb).
ABSTRACT
The phenomenon of growth in program size in genetic programming populations has been widely reported. In a variety of experiments and static analysis we test the standard protective code explanation and find it to be incomplete. We suggest bloat is primarily due to distribution of fitness in the space of possible programs and because of this, in the absence of bias, it is in general inherent in any search technique using a variable length representation.
We investigate the fitness landscape produced by program tree-based genetic operators when acting upon points in the search space. We show bloat in common operators is primarily due to the exponential shape of the underlying search space. Nevertheless we demonstrate new operators with considerably reduced bloating characteristics. We also describe mechanisms whereby bloat arises and relate these back to the shape of the search space. Finally we show our simple random walk entropy increasing model is able to predict the shape of evolved programs.
Bibliographic details (BibTeX html)
Technical report CSRP-98-17 (html).
ABSTRACT
We investigate the distribution of performance of the parity and always-on Boolean functions given only the appropriate building block. These problems have ``needle in a haystack'' fitness landscape and so are unsuitable for genetic programming or other progressive search techniques. Theoretical analysis shows in the limit as program size grows the density of solutions is independent of size but falls exponentially with number of inputs.
Earlier version was a late breaking paper at GP-98 (html) (poster). Also available as technical report CSRP-98-16
ABSTRACT
We investigate the distribution of performance of the Boolean functions of 3 Boolean inputs (particularly that of the parity functions), the always-on-6 and even-6 parity functions. We us enumeration, uniform Monte-Carlo random sampling and sampling random full trees. As expected XOR dramatically changes the fitness distributions. In all cases once some minimum size threshold has been exceeded, the distribution of performance is approximately independent of program length. However the distribution of the performance of full trees is different from that of asymmetric trees and varies with tree depth.
CSRP-98-16 Bibliographic details.
Report of the EvoGP Working Group on Genetic Programming of the European Network of Excellence in Evolutionary Computing
ABSTRACT
The problem of programming an artificial ant to follow the Santa Fe trail has been repeatedly used as a benchmark problem in GP. Recently we have shown performance of several techniques is not much better than the best performance obtainable using uniform random search. We suggested that this could be because the program fitness landscape is difficult for hill climbers and the problem is also difficult for Genetic Algorithms as it contains multiple levels of deception.
Here we redefine the problem so the ant is (1) obliged to traverse the trail in approximately the correct order, (2) to find food quickly. We also investigate (3) including the ant's speed in the fitness function, either as a linear addition or as a second objective in a multi-objective fitness function, and (4) GP one point crossover.
A simple genetic programming system, with no size or depth restriction, is shown to perform approximately three times better with the improved training function. (Extends CSRP-98-08)
ABSTRACT
The problem of programming an artificial ant to follow the Santa Fe trail has been repeatedly used as a benchmark problem. Recently we have shown performance of several techniques is not much better than the best performance obtainable using uniform random search. We suggested that this could be because the program fitness landscape is difficult for hill climbers and the problem is also difficult for Genetic Algorithms as it contains multiple levels of deception.
Here we redefine the problem so the ant is obliged to traverse the trail in approximately the correct order. A simple genetic programming system, with no size or depth restriction, is shown to perform approximately three times better with the improved training function.
ABSTRACT
The problem of programming an artificial ant to follow the Santa Fe trail is used as an example program search space. Analysis of shorter solutions shows they have many of the characteristics often ascribed to manually coded programs. Enumeration of a small fraction of the total search space and random sampling characterise it as rugged with many multiple plateaus split by deep valleys and many local and global optima. This suggests it is difficult for hill climbing algorithms. Analysis of the program search space in terms of fixed length schema suggests it is highly deceptive and that for the simplest solutions large building blocks must be assembled before they have above average fitness. In some cases we show solutions cannot be assembled using a fixed representation from small building blocks of above average fitness. These suggest the Ant problem is difficult for Genetic Algorithms.
Random sampling of the program search space suggests on average the density of global optima changes only slowly with program size but the density of neutral networks linking points of the same fitness grows approximately linearly with program length. This is part of the cause of bloat.
Previously reported genetic programming, simulated annealing and hill climbing performance is shown not to be much better than random search on the Ant problem.
ABSTRACT
In artificial evolution individuals which perform as their parents are usually rewarded identically to their parents. We note that Nature is more dynamic and there may be a penalty to pay for doing the same thing as your parents. We report two sets of experiments where static fitness functions are firstly augmented by a penalty for unchanged offspring and secondly the static fitness case is replaced by randomly generated dynamic test cases. We conclude genetic programming, when evolving artificial ant control programs, is surprisingly little effected by large penalties and program growth is observed in all our experiments.
ABSTRACT
In many cases programs length's increase (known as "bloat", "fluff" and increasing "structural complexity") during artificial evolution. We show bloat is not specific to genetic programming and suggest it is inherent in search techniques with discrete variable length representations using simple static evaluation functions. We investigate the bloating characteristics of three non-population and one population based search techniques using a novel mutation operator.
An artificial ant following the Santa Fe trail problem is solved by simulated annealing, hill climbing, strict hill climbing and population based search using two variants of the the new subtree based mutation operator. As predicted bloat is observed when using unbiased mutation and is absent in simulated annealing and both hill climbers when using the length neutral mutation however bloat occurs with both mutations when using a population.
We conclude that there are two causes of bloat 1) search operators with no length bias tend to sample bigger trees and 2) competition within populations favours longer programs as they can usually reproduce more accurately.
ABSTRACT
In many cases programs length's increase (known as ``bloat'', ``fluff'' and increasing ``structural complexity'') during artificial evolution. We show bloat is not specific to genetic programming and suggest it is inherent in search techniques with discrete variable length representations using simple static evaluation functions. We investigate the bloating characteristics of three non-population and one population based search techniques using a novel mutation operator.
An artificial ant following the Santa Fe trail problem is solved by simulated annealing, hill climbing, strict hill climbing and population based search using two variants of the the new subtree based mutation operator. As predicted bloat is observed when using unbiased mutation and is absent in simulated annealing and both hill climbers when using the length neutral mutation however bloat occurs with both mutations when using a population.
We conclude that there are two causes of bloat.
Presented at EuroGP '98 (LNCS 1391). (postscript) Late Breaking paper at GP-97 (poster). Also available as technical report CSRP-97-16
ABSTRACT
The problem of evolving, using mutation, an artificial ant to follow the Santa Fe trail is used to study the well known genetic programming feature of growth in solution length. Known variously as ``bloat'', ``fluff'' and increasing ``structural complexity'', this is often described in terms of increasing ``redundancy'' in the code caused by ``introns''.
Comparison between runs with and without fitness selection pressure, backed by Price's Theorem, shows the tendency for solutions to grow in size is caused by fitness based selection. We argue that such growth is inherent in using a fixed evaluation function with a discrete but variable length representation. With simple static evaluation search converges to mainly finding trial solutions with the same fitness as existing trial solutions. In general variable length allows many more long representations of a given solution than short ones. Thus in search (without a length bias) we expect longer representations to occur more often and so representation length to tend to increase. I.e. fitness based selection leads to bloat.
Position paper at Workshop on Evolutionary Computation with Variable Size Representation at ICGA-97, 20 July 1997, East Lansing, MI, USA. (Presentation slide)
ABSTRACT
We argue based upon the numbers of representations of given length, that increase in representation length is inherent in using a fixed evaluation function with a discrete but variable length representation. Two examples of this are analysed, including the use of Price's Theorem. Both examples confirm the tendency for solutions to grow in size is caused by fitness based selection.
Co author Riccardo Poli
Second best paper overall award at WSC2 (discussion at WSC2). Updates technical report CSRP-97-09
ABSTRACT
The problem of evolving an artificial ant to follow the Santa Fe trail is used to demonstrate the well known genetic programming feature of growth in solution length. Known variously as ``bloat'', ``redundancy'', ``introns'', ``fluff'', ``Structural Complexity'' with antonyms ``parsimony'', ``Minimum Description Length'' (MDL) and ``Occam's razor''. Comparison with runs with and without fitness selection pressure shows the tendency for solutions to grow in size is caused by fitness based selection. We argue that such growth is inherent in using a fixed evaluation function with a discrete but variable length representation. Since with simple static evaluation search converges to mainly finding trial solutions with the same fitness as existing trial solutions. In general variable length allows many more long representations of a given solution than short ones of the same solution. Thus with an unbiased random search we expect longer representations to occur more often and so representation length tends to increase. I.e. fitness based selection leads to bloat.
Co author Riccardo Poli
ABSTRACT
We present a detailed analysis of the evolution of GP populations using the problem of finding a program which returns the maximum possible value for a given terminal and function set and a depth limit on the program tree (known as the MAX problem). We confirm the basic message of \cite{Gathercole:1996:aicrtd} that crossover together with program size restrictions can be responsible for premature convergence to a sub-optimal solution. We show that this can happen even when the population retains a high level of variety and show that in many cases evolution from the sub-optimal solution to the solution is possible if sufficient time is allowed. In both cases theoretical models are presented and compared with actual runs.
Price's Covariance and Selection Theorem is experimentally tested on GP populations. It is shown to hold only in some cases, in others program size restrictions cause important deviation from its predictions.
Considerable update of CSRP-97-04
ABSTRACT
We investigate in detail what happens as genetic programming (GP) populations evolve. Since we shall use the populations which showed GP can evolve stack data structures as examples, we start in Section 1 by briefly describing the stack experiment In Section 2 we show Price's Covariance and Selection Theorem can be applied to Genetic Algorithms (GAs) and GP to predict changes in gene frequencies. We follow the proof of the theorem with experimental justification using the GP runs from the stack problem. Section 3 briefly describes Fisher's Fundamental Theorem of Natural Selection and shows in its normal interpretation it does not apply to practical GAs.
An analysis of the stack populations, in Section 4, explains that the difficulty of the stack problem is due to the presence of ``deceptive'' high scoring partial solutions in the population. These cause a negative correlation between necessary primitives and fitness. As Price's Theorem predicts, the frequency of necessary primitives falls, eventually leading to their extinction and so to the impossibility of finding solutions like those that are evolved in successful runs.
Section 4 investigates the evolution of variety in GP populations. Detailed measurements of the evolution of variety in stack populations reveal loss of diversity causing crossover to produce offspring which are copies of their parents. Section 5 concludes with measurements that show in the stack population crossover readily produces improvements in performance initially but later no improvements at all are made by crossover.
Section 6 discusses the importance of these results to GP in general.
ABSTRACT
In earlier work we showed that GP can automatically generate simple data types (stacks, queues and lists). The results presented herein show, in some cases, provision of appropriately structured memory can indeed be advantageous to GP in comparison with directly addressable indexed memory.
Three ``classic'' problems are solved. The first two require the GP to distinguish between sentences that are in a language and those that are not given positive and negative training examples of the language. The two languages are, correctly nested brackets and a Dyck language (correctly nested brackets of different types). The third problem is to evaluate integer Reverse Polish (postfix) expressions.
Comparisons are made between GP attempting to solve these problems when provided with indexed memory or with stack data structures.
The test cases are available. Bibliographic details.
ABSTRACT
In real world applications, software engineers recognise the use of memory must be organised via data structures and that software using the data must be independent of the data structures' implementation details. They achieve this by using abstract data structures, such as records, files and buffers.
We demonstrate that genetic programming can automatically implement simple abstract data structures, considering in detail the task of evolving a list. We show general and reasonably efficient implementations can be automatically generated from simple primitives.
A model for maintaining evolved code is demonstrated using the list problem.
Code is available. Bibliographic details. Original abstract, (May 1995) 4 pages.
ABSTRACT
This appendix contains bibliographic references to publications concerning genetic programming. Some effort has been made to make it as complete as possible but, like every such list, this is practically impossible and the list quickly becomes out of date as the field progresses. (click here for up to date online version). Nevertheless we hope that this appendix will prove a useful reference. The list is sorted into principle subject area. Within subject areas, publications are sorted by date (but works by the same author are grouped together).
Where on-line copies are available, the standard bibliographic reference is followed by the address of the on-line version using the Universal Reference Location (URL) format. Internet document servers are occasionally unavailable and are sometimes re-organized so documents may be moved to new URLs, therefore a degree of perseverance may be required to obtain on-line copies.
A small number of non-genetic programming papers have been included either for their historical significance or general interest to practitioners of genetic programming.
TABLE OF CONTENTS
B.1 Introductions to Genetic Programming
B.2 Surveys of Genetic Programming
B.3 Early Work on Genetic Algorithms that Evolve Programs
B.4 Some Early Genetic Programming References
B.5 GP Techniques and Theory
B.5.1 Different Representations for the Evolving Programs
B.5.1.1 Directed Graph Structured Programs
B.5.1.2 Strongly Typed GP -- Multiple Function and Data Types Within a Program
B.5.1.3 Using a Fixed or Evolving Syntax to Guide GP Search
B.5.1.4 Pedestrian GP -- Converting a Linear Chromosome to a Program
B.5.1.5 Stack Based GP -- Linear Chromosome Executed by Stack Based Virtual Machine
B.5.1.6 Machine Code GP -- Linear Chromosome Executed by CPU Directly
B.5.2 GP with other techniques
B.5.2.1 Minimum Description Length
B.5.2.2 Inductive Logic Programming
B.5.2.3 Binary Decision Trees
B.5.2.4 GP Classifiers
B.5.3 Functional and Data Abstraction
B.5.3.1 Automatically Defined Functions
Evolving ADF Architecture
B.5.3.2 Module Acquisition as Population Evolves
B.5.3.3 Adapting Program Primitives as Population Evolves
B.5.3.4 Abstract Data Types
B.5.4 Breeding Policies
B.5.4.1 Choosing Programs to Mate Using Geographic Closeness -- Demes
B.5.4.2 GP Running on Parallel Hardware
B.5.4.3 Choosing Programs to Mate Using Program Behaviour or Fitness -- Disassortive Mating
B.5.4.4 Selecting at Birth Which Programs Enter the Breeding Population
B.5.4.5 Seeding the Initial Population -- Population Enrichment and Incremental Learning
B.5.5 Indexed Memory or Genetic Programs that Explicitly Use Memory
B.5.6 Recursive and Iterative Genetic Programs
B.5.7 Fitness Evaluation
B.5.7.1 Fitness Depending Upon Other Individuals (in the Same or Different Populations, Co-Evolution)
B.5.7.2 Online Fitness as Testing Continues
B.5.7.3 How Good are Programs Evolved With Limited Tests on the General Problem?
B.5.7.4 Evaluation Efficiency
B.5.8 Genetic Operators
B.5.8.1 Targeting Crossover Points to Minimise Disruption
B.5.8.2 Hill Climbing and Simulated Annealing
B.5.9 GP Theory
B.5.9.1 Analyzing the GP Search Space as a Fitness Landscape
B.5.9.2 Analyzing GP Populations in Terms of Information Theory Entropy
B.5.9.3 GP Schema Theorem and Building Block Hypothesis
B.5.9.4 Evolvability of GP Populations
B.5.9.5 Evolution of Program Size and Non-Functional Code (Introns)
B.5.9.6 Statistical Approaches to Fitness Distributions within GP Populations
B.6 GP Development Systems
B.7 GP Applications
B.7.1 Prediction and Classification
B.7.2 Modeling
B.7.3 Image and Signal Processing
B.7.4 Optimisation of Designs
B.7.5 Database
B.7.6 Financial Trading, Time Series Prediction and Economic Modeling
B.7.7 Robots and Autonomous Agents
B.7.8 Planning
B.7.9 Control
B.7.10 Computer Language Parsing
B.7.11 Medical
B.7.12 Artificial Life
B.7.13 Game Theory
B.7.14 Computer Application Porting
B.7.15 Neural Networks
B.7.16 Simulated Annealing
B.7.17 Fuzzy Logic
B.7.18 Artistic
B.7.18.1 Music
B.7.18.2 Entertainment
B.7.19 Scheduling and other Constrained Problems
B.7.20 Highly Reliable Computing
B.8 Collected Works and Bibliographies
B.9 Book Reviews
B.10 Comparison With Other Techniques
B.11 Patents
B.12 Other uses of the term ``Genetic Programming''
B.13 Some Other Genetic Algorithms Approaches to Program Evolution
co-author Adil Qureshi
ABSTRACT
Computers that ``program themselves''; science fact or fiction? Genetic Programming uses novel optimisation techniques to ``evolve'' simple programs; mimicking the way humans construct programs by progressively re-writing them. Trial programs are repeatedly modified in the search for ``better/fitter'' solutions. The underlying basis is Genetic Algorithms (GAs).
Genetic Algorithms, pioneered by Holland, Goldberg and others, are evolutionary search techniques inspired by natural selection (i.e\ survival of the fittest). GAs work with a ``population'' of trial solutions to a problem, frequently encoded as strings, and repeatedly select the ``fitter'' solutions, attempting to evolve better ones. The power of GAs is being demonstrated for an increasing range of applications; financial, imaging, VLSI circuit layout, gas pipeline control and production scheduling. But one of the most intriguing uses of GAs - driven by Koza - is automatic program generation.
Genetic Programming applies GAs to a ``population'' of programs - typically encoded as tree-structures. Trial programs are evaluated against a ``fitness function'' and the best solutions selected for modification and re-evaluation. This modification-evaluation cycle is repeated until a ``correct'' program is produced. GP has demonstrated its potential by evolving simple programs for medical signal filters, classifying news stories, performing optical character recognition, and for target identification.
This paper surveys the exciting field of Genetic Programming. As a basis it reviews Genetic Algorithms and automatic program generation. Next it introduces Genetic Programming, describing its history and describing the technique via a worked example in C. Then using a taxonomy that divides GP research into theory/techniques and applications, it surveys recent work from both of these perspectives.
Extensive bibliographies, glossaries and a resource list are included as appendices. },
Code is available. Bibliographic details.
Code is available. Bibliographic details.
ABSTRACT
Genetic programming (GP) is a subclass of genetic algorithms (GAs), in which evolving programs are directly represented in the chromosome as trees. Recently it has been shown that programs which explicitly use directly addressable memory can be generated using GP.
It is established good software engineering practice to ensure that programs use memory via abstract data structures such as stacks, queues and lists. These provide an interface between the program and memory, freeing the program of memory management details which are left to the data structures to implement. The main result presented herein is that GP can automatically generate stacks and queues.
Typically abstract data structures support multiple operations, such as put and get. We show that GP can simultaneously evolve all the operations of a data structure by implementing each such operation with its own independent program tree. That is, the chromosome consists of a fixed number of independent program trees. Moreover, crossover only mixes genetic material of program trees that implement the same operation. Program trees interact with each other only via shared memory and shared ``Automatically Defined Functions'' (ADFs).
ADFs, ``pass by reference'' when calling them, Pareto selection, ``good software engineering practice'' and partitioning the genetic population into ``demes'' where also investigated whilst evolving the queue in order to improve the GP solutions.
Code is available. Bibliographic details.
Bibliographic details.
ABSTRACT
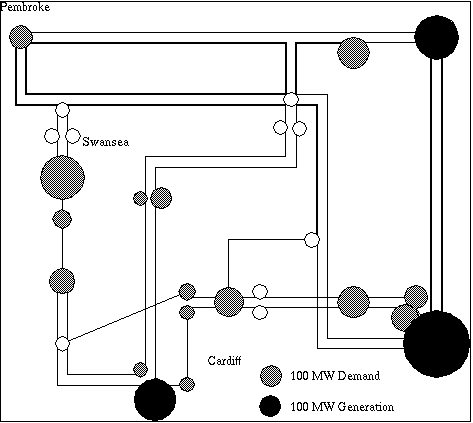
Summary of Genetic Algorithm and Genetic programming work on evolving schedules for preventative maintenance of the South Wales region of the UK high voltage electricity network.
Bibliographic details.
ABSTRACT
National Grid Plc is responsible for the maintenance of the high voltage electricity transmission network in England and Wales. It must plan maintenance so as to minimize costs taking into account:
This paper describes the evolution of the best known schedule for the base South Wales problem using Genetic Programming starting from the hand coded heuristics used with the GA.
Bibliographic details.
ABSTRACT
This paper builds on previous work, applying the combination of a greedy scheduler and permutation GA to the South Wales region of the UK National Grid. In this paper the work is extended to consider continuing to supply electricity is the presence of faults on the network.
Bibliographic details.
Also available as Technical Report CSRP-96-18
Version presented at the AISB Workshop. pp. 132-153 (Springer) (postscript).
ABSTRACT
National Grid Plc is responsible for the maintenance of the high voltage electricity transmission network in England and Wales. It must plan maintenance so as to minimize costs taking into account:
This paper reports work in progress. So far:
Code is available Bibliographic details.
ABSTRACT
A description of a use of Pareto optimality in genetic programming is given and an analogy with Genetic Algorithm fitness niches is drawn. Techniques to either spread the population across many Pareto optimal fitness values or to reduce the spread are described. It is speculated that a wide spread may not aid Genetic Programming. It is suggested that this might give useful insight into many GPs whose fitness is composed of several sub-objectives.
The successful use of demic populations in GP leads to speculation that smaller evolutionary steps might aid GP in the long run.
An example is given where Price's covariance theorem helped when designing a GP fitness function.
Bibliographic details.
ABSTRACT
Describes in detail a mechanism used to bias the choice of crossover locations when evolving a list data structure using genetic programming. The data structure and it evolution will be described in Advances in Genetic Programming 2.
The second section describes current research on biasing the action of reproduction operators within the genetic programming field.
Bibliographic details.
ga-nk-summary.txt 300 lines
ga-seed.txt 150 lines
ABSTRACT
Wouldn't it be great if computers could actually write the programs? This is the promise of genetic programming. This document gives an introduction to the program simple-gp.c which demonstrates the principles of genetic programming in the C language. This program was designed to show the ideas behind GP, ie to be tinkered with rather than to be a definitive implementation.
The appendix contains a glossary of evolutionary computing terms
Code. Bibliographic details.
{kind=link}
{kind=link}