There may be a critical point in the life cycle that might be disrupted by a drug. E.g. a point where a chemical might bind and prevent the diseases action.
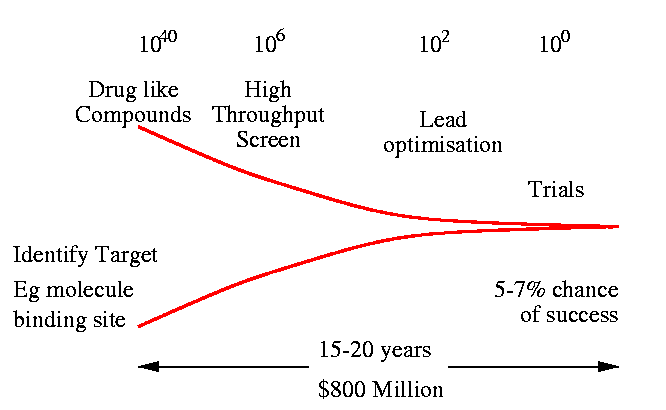
Search space of potential drugs is huge.
Estimated ![]() drug like chemicals.
drug like chemicals.
Using high throughput robot based screening
in the region of ![]() can be measured.
can be measured.
Computer models are used at many stages of the discovery ``funnel''. They guide chemists as to where to look next.
Models predict as yet unmeasured properties.
They can screen ``virtual'' chemicals,
i.e. chemicals that do not exist.
Virtual chemicals
could be manufactured,
if the computer suggested they might be interesting.
Train on former SKB training data.
Test on former SKB.
Extrapolate to former GW.
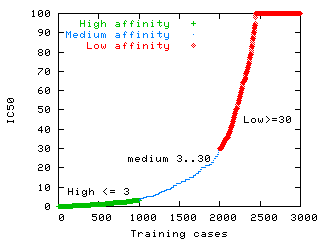
Continuous P450 IC50 measurement divided into three classes. Inhibitory, Substrate and Inactive.
| 3000 | ( | 1000, | 1000, | 1000) | training fSKB | (IC50 given) | ||||
| 4570 | ( | 91, | 1563, | 2916) | test fSKB | (no IC50) | ||||
| 1932 | ( | 114, | 446, | 1372) | extrapolation set fGW | (no IC50). |
Features are domain knowledge. They can be Boolean, categorical or continuous.
They represent chemical properties. E.g. charge imbalance, acid or base, heavy metal.
Training data was deliberately set up to have equal numbers in each of the three classes.
The test (or interpolation) data set and the extrapolation set very unequal split.
(Might have been better to use
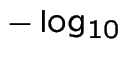 IC50
(pIC50)
instead?)
IC50
(pIC50)
instead?)
For GP, the training data was randomly split into train and verification (2:1).
Classification via regression (least squared error).
I.e. Evolve prediction of continuous IC50 value,
then place in one of the three class bins.
Direct classification (3 classes).
Arithmetic operations, IFLTE, min, max, etc.
121 features, 0,1,2,...,9 and 90 randomly chosen constants
![]() of 3000 labelled data used as training cases.
of 3000 labelled data used as training cases.
Fitness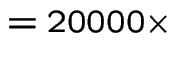 hits
hits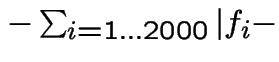 IC50
IC50![]()
(a hit is a correctly classified example after thresholding)
Size fair crossover, mutations. Population size 5000, 50 generations
Best of five runs
Arithmetic operations, IFLTE, min, max, etc.
121 features, 0,1,2,...,9 and 90 randomly chosen constants
![]() of 3000 labelled data used as training cases
of 3000 labelled data used as training cases
fitness = hits
Size fair crossover, mutations. Population size 5000, 50 generations
Best of five runs
Best of 5 regression runs and 5 classifications runs are plotted together with best simplified model of both GP approaches.
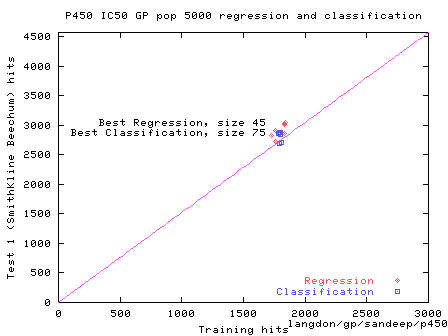
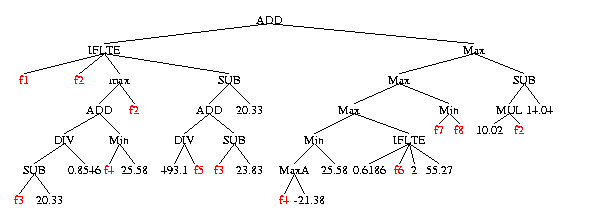
F1, f2, ... f8 are GSK domain specific features calculated for each chemical from its chemical formula. These 8 features were chosen by GP from the 121 available.
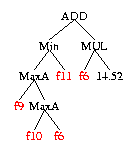
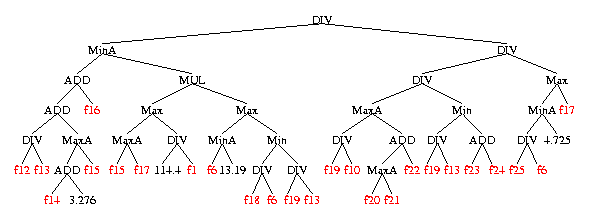
Substrate
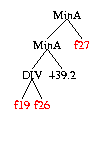
Inactive
using small number of features,
and those features made sense to p450 modelling experts.
If it fits on a slide put it on slide!